Simple NN with Flax.#
![]()
This notebook trains a simple one-layer NN with Optax and Flax. For more advanced applications of those two libraries, we recommend checking out the cifar10_resnet example.
import jax
import jax.numpy as jnp
import optax
import matplotlib.pyplot as plt
from flax import nnx
# @markdown Learning rate for the optimizer:
LEARNING_RATE = 1e-2 # @param{type:"number"}
# @markdown Number of training steps:
NUM_STEPS = 100 # @param{type:"integer"}
# @markdown Number of samples in the training dataset:
NUM_SAMPLES = 20 # @param{type:"integer"}
# @markdown Shape of the input:
X_DIM = 10 # @param{type:"integer"}
# @markdown Shape of the target:
Y_DIM = 5 # @param{type:"integer"}
In this cell, we initialize a random number generator (RNG) and use it to create separate RNGs for all randomness-related things.
rng = jax.random.PRNGKey(0)
params_rng, w_rng, b_rng, samples_rng, noise_rng = jax.random.split(rng, num=5)
In the next cell, we define a model and obtain its initial parameters.
# Creates a one linear layer instance.
model = nnx.Linear(in_features=X_DIM, out_features=Y_DIM, rngs=nnx.Rngs(params_rng))
In the next cell we generate our training data.
We will be approximating a function of the form y = wx + b, hence why we generate w, b, training samples x and obtain y, using the formula above.
# Generates ground truth w and b.
w = jax.random.normal(w_rng, (X_DIM, Y_DIM))
b = jax.random.normal(b_rng, (Y_DIM,))
# Generates training samples.
x_samples = jax.random.normal(samples_rng, (NUM_SAMPLES, X_DIM))
y_samples = jnp.dot(x_samples, w) + b
# Adds noise to the target.
y_samples += 0.1 * jax.random.normal(noise_rng, (NUM_SAMPLES, Y_DIM))
Next we define a custom MSE loss function.
def make_mse_func(x_batched, y_batched):
def mse(model):
# Defines the squared loss for a single (x, y) pair.
def squared_error(x, y):
pred = model(x)
return jnp.inner(y-pred, y-pred) / 2.0
# Vectorizes the squared error and computes mean over the loss values.
return jnp.mean(jax.vmap(squared_error)(x_batched, y_batched), axis=0)
return jax.jit(mse) # `jit`s the result.
# Instantiates the sampled loss.
loss = make_mse_func(x_samples, y_samples)
# Creates a function that returns value and gradient of the loss.
loss_grad_fn = jax.value_and_grad(loss)
In the next cell, we construct a simple Adam optimizer using Optax gradient transformations passed to the optax.chain.
The same result can be achieved by using the optax.adam alias. However, here, we demonstrate how to work with gradient transformations manually so that you can build your own custom optimizer if needed.
tx = optax.chain(
# Sets the parameters of Adam. Note the learning_rate is not here.
optax.scale_by_adam(b1=0.9, b2=0.999, eps=1e-8),
# Puts a minus sign to *minimize* the loss.
optax.scale(-LEARNING_RATE)
)
We then pass the initial parameters of the model to the optimizer to initialize it.
optimizer = nnx.Optimizer(model, tx, wrt=nnx.Param)
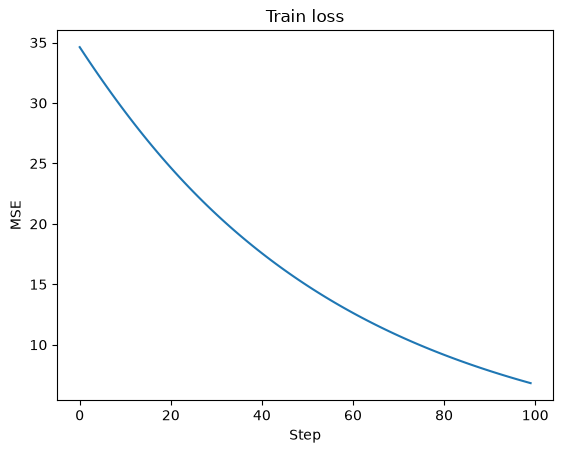
Finally, we train the model for NUM_STEPS steps.
loss_history = []
# Minimizes the loss.
for _ in range(NUM_STEPS):
# Computes gradient of the loss.
loss_val, grads = loss_grad_fn(model)
loss_history.append(loss_val)
# Updates the optimizer state and the parameters.
optimizer.update(model, grads)
plt.plot(loss_history)
plt.title('Train loss')
plt.xlabel('Step')
plt.ylabel('MSE')
plt.show()